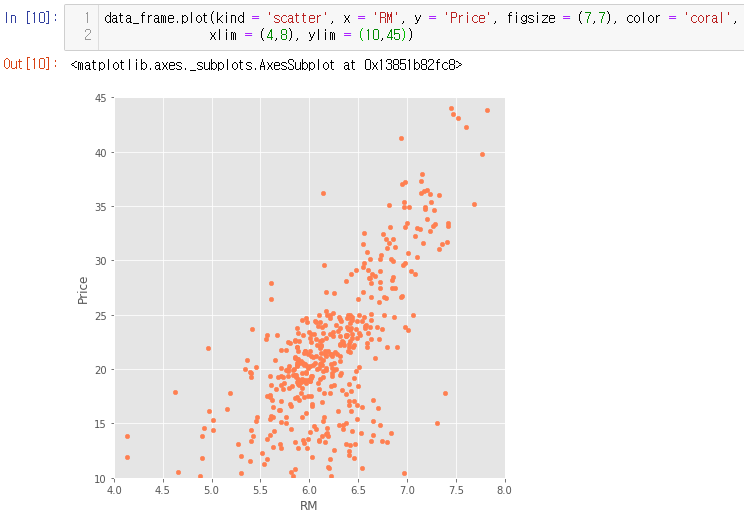
자 이제 주어진 정제된 데이터 중 방의 수와 집값의 관계를 알아보도록 하겠다. 표에 나와있는 숫자들들 일일이 비교하기에는 시간도 너무 많이 걸리고 직관적이지 않다. 일일이 비교하면 파이썬을 사용하는 의미가 없다. 방의 수와 집값이 어떤 관계가 있는지 알아보기 위해 산점도를 그려보도록 하겠다. 산점도는 서로 다른 수 변수 사이의 관계를 보여준다.

산점도를 그리기 위해 plot() 메서드를 사용한다. ( ) 안에 그래프의 종류, x 축의 값, y 축의 값, 크기, 점 색깔 등을 넣어주면 된다. 어느 정도 양의 관계가 있는 것처럼 보이는데 자세히 보면 소수의 랜덤한 값들이 있는 것을 알 수가 있다. 보기에도 안 좋고 상관관계를 분석하는데 잘못된 영향을 끼칠 수 있기 때문에 삭제해 준다. 참고로 아래 그림은 ggplot을 사용하지 않았을 경우 보이는 그래프이다.

ggplot을 안 쓰면 못생겨진다
그래프를 자르기 위해 일정 범위 안의 값만 나타내주는 xlim, ylim을 사용했다
이제 방의 수와 집값의 상관관계를 분석하기 위해 단순선형회귀식을 구해야 한다. sklearn 라이브러리의 선형회귀분석 모듈을 이용한다면 아주 쉽게 구할 수 있다.


sklearn 라이브러리의 LinearRegression() 함수로 회귀분석 모형 객체를 생성하여 linear_regression에 저장한다. 모형 객체에 fit() 메서드를 적용하면 알파와 베타를 구할 수 있다. linear_regression.coef_는 베타값 즉 기울기를 구해주고 linear_regression.intercept_는 알파값 즉 y 절편을 구해준다. 4번은 잔차를 구할 때 Y의 예측 값을 빼줘야 하기 때문에 구해줬다.

잔차를 구한 후 SSE(Sum of Squares Error), SST(Sum of Squares Total)를 구해 결정계수인 R^2를 구해보았다. 결정계수는 예측 능력을 평가하기 위해 구하는 값으로 결정계수의 값이 클수록 모형의 예측 능력이 좋다고 본다. 사실 이 복잡한 과정을 거치지 않아도 쉽게 구할 수 있는 방법이 있다.

결정계수가 높은 편은 아니지만 위에 그린 산점도에 선형회귀곡선도 그려 관계를 파악해보겠다.

'빅데이터' 카테고리의 다른 글
| 특정 데이터 값 변경(replace함수) (0) | 2020.10.19 |
|---|---|
| drop 함수, 인덱스 리셋 (0) | 2020.10.19 |
| 상관계수와 미세먼지 데이터 (0) | 2020.10.19 |
| 과소적합(Underfitting) 그리고 과적합(Overfitting) (0) | 2020.10.19 |
| 단순선형회귀분석과 보스턴 집값 데이터(1) (0) | 2020.10.17 |



